New computational tool Coralysis helps scientists interpret complex single-cell data
Researchers from Turku Bioscience Centre at University of Turku have developed a new computational method to interpret complex single-cell data.
The human body contains about 37 trillion cells. Some are more alike than others, yet never exactly the same. Modern single-cell technologies allow characterizing this cellular heterogeneity, measuring dozens to thousands of molecules, such as genes or proteins, across thousands of individual cells simultaneously and providing insights into health and diseases.
A small amount of blood contains billions of red blood cells and millions of immune cells. Each type of cell has its own molecular ‘fingerprint’, which researchers can identify by combining single-cell technologies with computational methods.
When studying many different samples, scientists must first match the same cell types across them. This is a demanding step known as data integration.
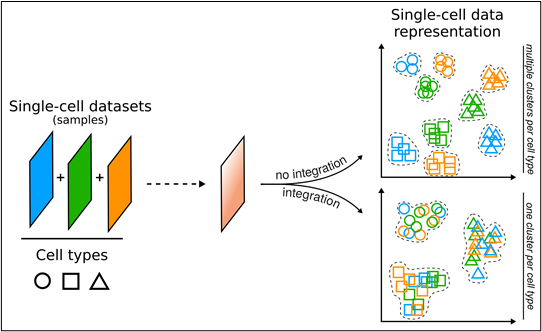
However, current integration methods often struggle when cell types vary between samples or appear in very different amounts. In such cases of imbalanced data, methods can mistakenly combine distinct cell types.
To solve this, researchers from University of Turku, Finland, have now developed a new machine learning-based algorithm that effectively integrates even imbalanced data across samples. The method, named Coralysis, has been developed at Turku Bioscience Centre in Professor Laura Elo’s Computational Biomedicine research group, which is also affiliated with the InFLAMES flagship.
“Single-cell technologies let us study the incredible diversity of cells, but comparing them across samples is tricky. This motivated us to develop a method to uncover these hidden patterns reliably”, says Associate Professor Sini Junttila, one of the supervisors of the study.
Effective open-source tool
“We were inspired by the process of assembling a puzzle where one begins by grouping pieces based on low- to high-level features such as colour and shading before looking at shape and patterns. Similarly, our algorithm progressively integrates cellular identities through multiple rounds of divisive clustering”, explains doctoral researcher António Sousa, the lead developer of Coralysis.
Coralysis has been implemented as an open-source software. At its core, it relies on machine learning, enabling it to build models that can be used to predict cellular identities in new datasets and even estimate how confident the predictions are. This helps researchers avoid the cumbersomeand often unreliable task of manually identifying cell types. Another unique feature of Coralysis is its ability to detect changing cellular states that might otherwise be missed.
“Coralysis provides the scientific community with a new way to study cellular diversity and gain a deeper understanding of complex single-cell data. By making it openly available, we hope to support collaboration and accelerate discoveries across the global research community”, says Professor Laura Elo, the principal investigator of the project.
The study by Elo group has been published in the scientific journal Nucleic Acids Research.
Read the article Coralysis enables sensitive identification of imbalanced cell types and states in single-cell data via multi-level integration